AI界地震!昆仑万维重磅开源:多模态推理模型R1V炸裂来袭!
昆仑万维开源Skywork R1V多模态推理模型,开启视觉思考新纪元
3月18日,中国AI领军企业昆仑万维宣布正式开源其首款工业级多模态思维链推理模型——Skywork R1V。这一举措标志着中国企业在多模态AI领域迈出了重要一步,为全球开发者和研究者提供了强大的开源工具。Skywork R1V的开源模型权重和技术报告现已发布,开发者可以立即下载并开始使用。
Skywork R1V模型权重及技术报告下载
模型权重下载地址
- Hugging Face:https://huggingface.co/Skywork/Skywork-R1V-38B
- GitHub:https://github.com/SkyworkAI/Skywork-R1V
详细技术报告地址
视觉推理模型是一种能够解决需要复杂思考过程的视觉任务的人工智能模型。它不仅仅是识别图像中的内容,更重要的是,它能够像人类一样,对视觉信息进行多步骤的逻辑推理和分析,逐步推导出最终的结论。这种模型能够胜任视觉逻辑推理、视觉数学问题、图像中的科学现象分析、医学影像诊断等任务,极大地拓展了视觉大模型的应用范围。简而言之,Skywork R1V 能够处理日常工作、数据分析、学术难题,乃至前所未见的复杂场景。
Skywork R1V的卓越性能
Skywork R1V 在推理和视觉理解方面都表现出了强大的能力,这得益于其在Reasoning推理能力和Vision视觉理解能力上的突破。通过深度融合视觉与文本能力,Skywork R1V 推动了多模态推理模型的发展,标志着人工智能领域的又一重大进步。目前,Skywork R1V 已全面开源,旨在推动全球学术研究与产业应用探索。
推理能力:领先的逻辑与数学分析
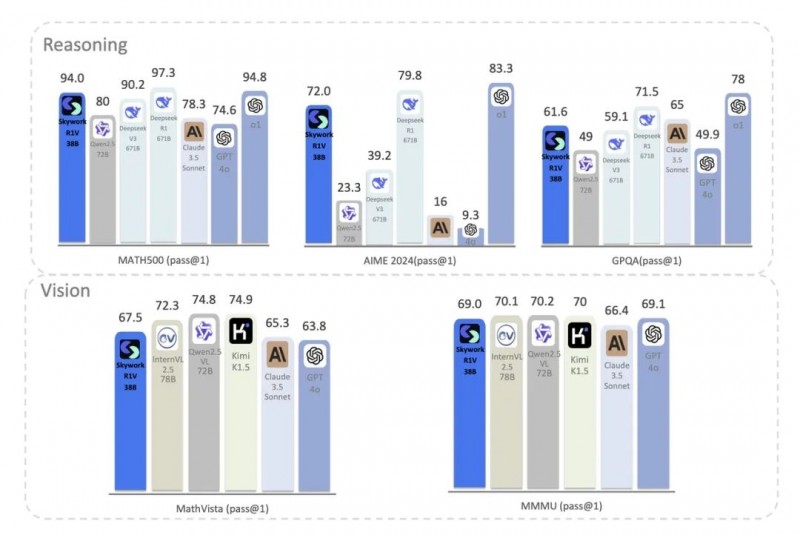
在 Reasoning 推理能力方面,Skywork R1V 实现了顶尖的逻辑推理与数学分析能力。在权威的 MATH500 和 AIME 基准测试中,Skywork R1V 分别取得了 94.0 和 72.0 的高分,显著领先于行业内众多主流模型。这表明,Skywork R1V 在纯文本复杂推理任务中展现出了卓越性能,使其在逻辑推理和数学问题求解领域达到了专家级别的水准。
视觉理解能力:跨模态任务的突破
在 Vision 视觉理解能力方面,Skywork R1V 成功地将强大的文本推理与思维链推导能力高效迁移到了视觉任务中。凭借创新的跨模态迁移技术与推理优化框架,Skywork R1V 能够高效解决需要多步视觉推理的问题,在 MMMU 与 MathVista 等视觉推理基准中分别取得了 69 和 67.5 的优异成绩。这些结果不仅明显超越了多个近似大小的开源竞争模型,更达到了与规模更大的闭源模型媲美的水准,充分证实了 Skywork R1V 在需要视觉思维链推理的跨模态任务中的领先优势。
性能对比:R1V与行业标杆
与开源同规模或更大规模的模型相比,Skywork R1V 38B 体现出行业显著优异的推理能力以及领先的多模态视觉理解能力。

与闭源头部模型性能对比,R1V 38B 模型性能媲美甚至超越更大开源模型以及主流闭源模型。
三大核心技术创新
Skywork R1V 能够达到当前的性能高度,依赖于以下三项关键技术创新:
文本推理能力的多模态高效迁移
多模态混合式训练(Iterative SFT+GRPO)
自适应长度思维链蒸馏
文本推理能力的多模态高效迁移
昆仑万维团队首次提出利用 Skywork-VL 的视觉投影器,无需重新训练语言模型和视觉编码器,即可实现文本推理能力的高效迁移到视觉任务,同时保留了优秀的原本推理文本能力 (AIME 72.0,MATH500 94.0)。
多模态混合式训练(Iterative SFT+GRPO)
通过结合迭代监督微调 (Iterative SFT) 和 GRPO 强化学习,分阶段对齐视觉-文本表征,实现跨模态任务的高效融合,极大提升跨模态任务的表现。推动模型在 MMMU 基准达到 69 分的能力,同时在 MathVista 达到 67.5 分,与更大规模的闭源模型基本持平。通过反复迭代地利用高质量数据与高难度数据的组合,实现模型持续的知识巩固与错误纠正,显著提升了多模态推理的精度与泛化性能。

图丨多模态混合式训练(来源:Skywork R1V技术报告)
自适应长度思维链蒸馏
团队提出了一种基于视觉-文本复杂度的自适应推理链长度控制机制,动态优化模型推理过程,避免模型“过度思考”,提升推理效率。结合多阶段自蒸馏策略,进一步提升了数据生成与推理过程的质量,促进了模型在复杂多模态任务中的表现。

图丨自适应长度思维链蒸馏(来源:Skywork R1V技术报告)
R1V训练策略:三阶段方法
Skywork R1V 在训练过程中创新性地采用了三阶段方法,使得文本端强大的推理能力得以高效迁移至视觉任务上。具体训练流程如下:
STEP1 视觉语言表征的初始对齐
STEP2 推理能力迁移
STEP3 视觉与文本模态精准对齐
STEP1 视觉语言表征的初始对齐
训练时首先使用轻量级的视觉适配器 (MLP) 连接视觉编码器 (ViT) 与语言模型,在已有的 200 万条常规多模态数据上进行训练,使得 MLP 初步学习如何将图像特征映射至语言空间。这一阶段仅训练 MLP 适配器,视觉编码器和语言模型参数保持冻结不变,快速、高效地实现视觉与语言表征的初步对齐。
STEP2 推理能力迁移
利用第一阶段训练好的 MLP 适配器,直接将视觉编码器与原始的强推理语言模型 (R1-distilled-Qwen-32B) 连接,形成 Skywork-R1V 视觉推理模型。虽然此时语言模型的参数发生了改变,但得益于语言模型架构的高度相似性和 MLP 的泛化能力,重新组装后的模型已能表现出一定的视觉推理能力,初始性能即达到业内同等规模的先进水平。
STEP3 视觉与文本模态精准对齐
最后,采用创新的“混合优化框架”,进一步精准对齐视觉和语言模态的表征。这一阶段分为两大步骤:迭代监督微调 (Iterative SFT) 和群组相对策略优化 (GRPO) 强化学习。在整个训练过程中,Skywork-R1V 还创新性地引入了“自适应长度思维链蒸馏技术”,动态优化推理链长度,防止模型过度思考,从而提升了推理效率和质量。 通过以上的训练策略,Skywork R1V 在视觉推理任务上取得突破性进展,并在多个公开评测基准中达到或超过了现有领先模型的性能。
未来展望:全模态理解模型
此外,Skywork 团队多模态理解模型也在进行 “全面贯通” 的进化,将视觉多模态扩展为全模态模型,引入语音理解能力。当前,全模态模型往往受限于特定领域不仅需要独立训练多个专业模型,更面临跨模态协同的算力挑战。
基于 R1V 模型,Skywork 团队设计了一种灵活在 R1V 中扩展语音理解模态的方式,从而实现一个全模态思考大模型,该在单个模型中同时实现图像、视频、语音的全模态理解能力,并在语音和视觉理解评测中斩获多项 SOTA 成绩。我们将陆续公布测评成绩、开源全模态思考大模型。
昆仑万维的开源承诺与AGI愿景
自2023年10月以来,昆仑万维持续向开源社区贡献力量,陆续开源了百亿级大语言模型「天工」Skywork-13B系列、数字智能体全流程研发工具包AgentStudio、4000亿参数MoE超级模型、2千亿稀疏大模型Skywork-MoE、推理模型Skywork-o1-Open等。2025年2月18日,昆仑万维同时将SOTA级别的SkyReels-V1和SkyReels-A1进行开源。
在语言生成模型、AI Agent、推理模型、视频生成模型等相继开源、多点开花之后,我们正式开源Skywork R1V多模态推理模型,在文本-视觉多模态推理方向再下一城,成为中国第一家开源多模态思考模型的企业。
中国企业过去一年在AI领域的开源贡献,让全世界AI从业者和开发者享受到了技术共享带来的普惠发展。DeepSeek的开源为AI行业提供了新的发展范本,多项开源成果显著降低了AI技术的应用门槛、促进全球AI技术的民主化。昆仑万维作为中国AI领军企业,我们将持续开源优秀的模型、数据集等,共建开发者生态、加速技术创新、降低应用门槛、推动技术平权和AI行业发展。

帕洛阿尔托
MORE>-

付鹏演讲解读:中国经济面临的严峻挑战与未来趋势
东北证券首席经济学家付鹏近期在汇丰银行发表的演讲引发广泛关注,其核心...
-

2025年投资风向标:聚焦算力与AI主题ETF
算力已成为国家竞争力的重要标志,人工智能时代的到来更是加速了全球在算...
-

中粮信托2024年财务报表发布及区块链技术应用展望
中粮资本发布了中粮信托有限责任公司2024年财务报表(未经审计),这...
-

币安Web3钱包参与Ton生态活动瓜分NFT、代币等奖励
币安官方推出了一项活动,只要使用币安Web3钱包参与Ton生态,就能...
-

Floki Inu (FLOKI) 2025年价格预测:谨慎乐观
本文对FlokiInu(FLOKI)代币在2025年的价格走势...
-
数据很振奋人心!尤其境外支付增长这么快,说明中国经济复苏和国际影响力都在提升...
-
信息量挺大的,分析比较全面,特别是提到了整合风险和市场风险,比较务实。不过文...
-
DeepSeek大模型多平台上线,降低了AI开发门槛,这对于区块链行业应用开...
-
 雨夜沉默 评论文章:方便快捷的加密货币支付卡,解决了加密货币兑换法币的痛点,尤其对经常进行跨境支...
雨夜沉默 评论文章:方便快捷的加密货币支付卡,解决了加密货币兑换法币的痛点,尤其对经常进行跨境支... -
数据显示保险业发展迅速,但赔付增速过高值得关注。区块链技术应用前景广阔,期待...
- 最近发表
-
- Memecoin迷因金融風暴:苗博雅談監管挑戰,孔令奇式創新能否救贖?
- Solana 新星 Believe:創投 Meme 化突圍?威力彩槓龜下的新選擇
- SOON幣空投:KOL盛宴?幣安CZ站臺疑雲,苗博雅來擼或成贏家
- SOON代幣空投啟動:幣安Alpha上線,社群情緒與交易策略分析
- AI智磐破局:齊心集團AI重塑政企採購,提升效率與決策力
- Solana革新:Alpenglow共識機制挑戰傳統,媲美Web2速度
- AI独角兽陨落?云知声血亏12亿,上市路坎坷,豪赌大模型胜算几何?
- AI泡沫破灭?搜狐科技论坛揭秘行业真相,大佬预警信息危机!
- 阿里财报暴跌:AI云计算泡沫破裂?中国AI增长困境曝光
- 科技金融新政:豪赌还是强心针?自立自强背后暗藏玄机